intellij idea下本地调试spark程序,打包程序使用的是maven
环境准备
- java version “1.8.0_211”
- Scala code runner version 2.11.12
- intellij idea 2019.1
- intellij idea plugin: scala v2019.1.8
创建项目
打开idea,然后选择新建项目,选择maven![maven_create]](https://pic-1251286439.cos.ap-guangzhou.myqcloud.com/it/intellij/spark/Screenshot%202019-09-26%20at%2013.51.35.png)
输入对应groupid、artifactid跟version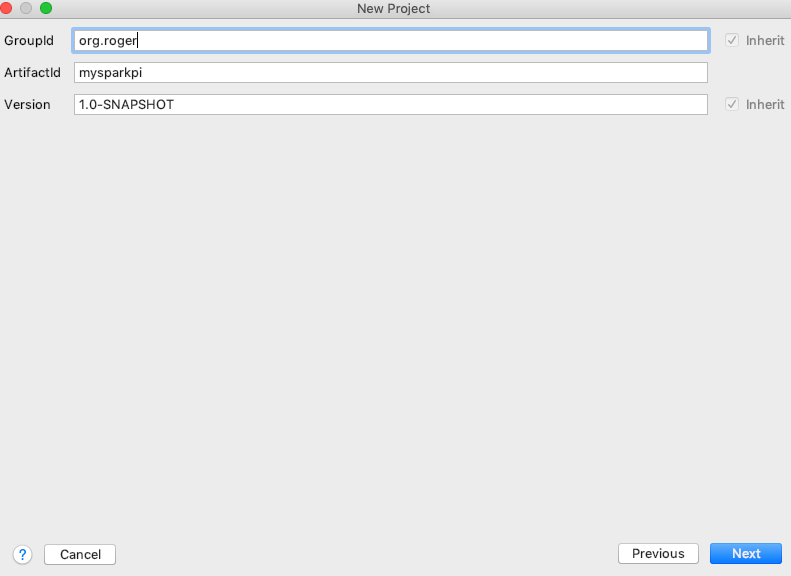
选择代码目录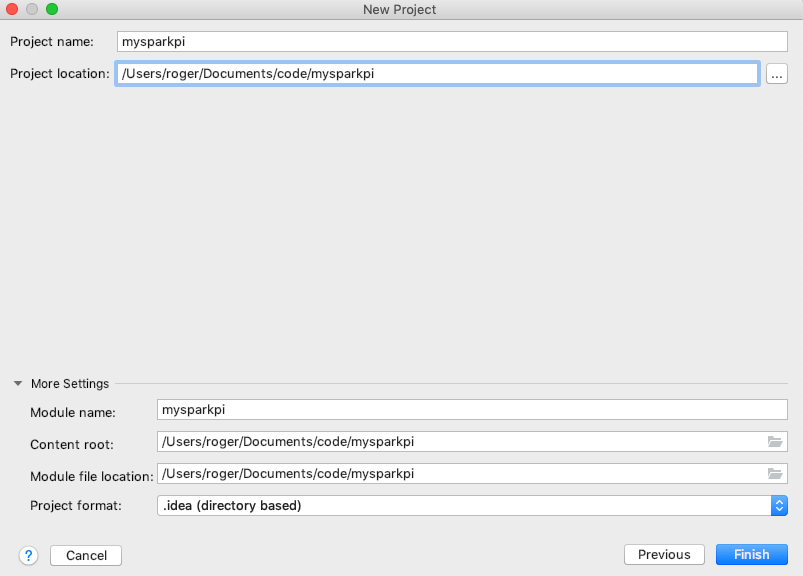
代码创建后项目结构如下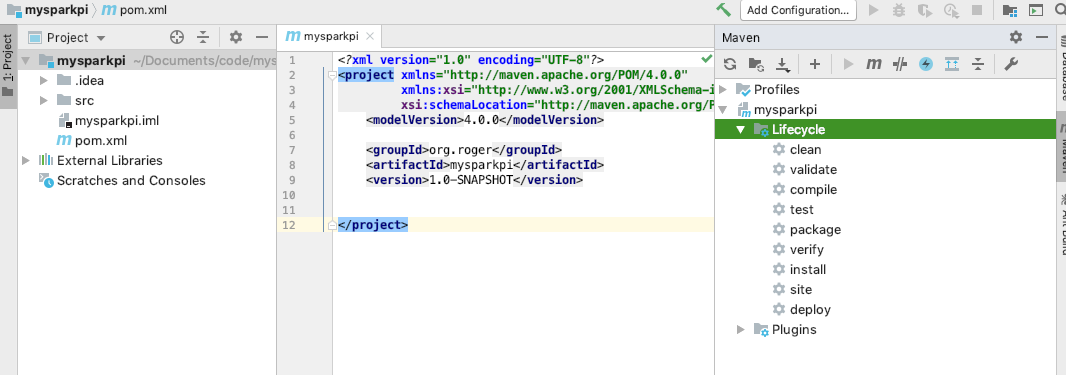
配置pom文件
增加spark依赖跟maven编译设置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.3</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
</includes>
</configuration>
</execution>
<execution>
<id>scala-test-compile</id>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<addMavenDescriptor>false</addMavenDescriptor>
<manifest>
<addClasspath>false</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>TestPi</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
注意这里版本需要根据实际情况
增加测试代码
- 在src/main下增加文件夹scala,因为maven会默认选择读取src/main/java跟src/main/scala下代码文件
- 同时将新建的文件夹设置成source
- 右键scala文件夹点击new,这时会看到有scala文件

- 增加object代码
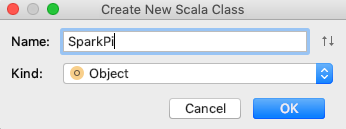
- 使用如下代码到SparkPi中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22package SparkPi
import scala.math.random
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object SparkPi {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("My SparkPi")
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}
编译调试项目
- 输入
mvn compile或者直接选择maven视窗下选择mysparkpi/lifecycle/compile来编译 - 编译成功后,直接点击main函数对应的绿色三角按钮,运行项目
输出结果如下:
1
Pi is roughly 3.1436157180785904
尝试断点也可以运作

